

What is data engineering?
Data engineering is the process of designing and building systems for acquiring large amounts of raw operational data from various sources and formats, analysing it, transforming it, and storing it at scale. The management of the data infrastructure is a particular focus of data engineering. Data engineering is usually regarded as the primary support for present data analytics needs.
Data is handled by various technologies and stored in a variety of forms and structures, making data analysis difficult. Hence, we need the right specialists (data engineers) and technology to unify various data sets so that they remain available and usable for further analysis by data analysts and scientists.
The first step in data engineering is obtaining vast quantities of data from a variety of sources and bringing them to a data lake or any other big data platform. We call this as data ingestion. Once the data has been landed in the data lake, data curation is carried out. Data curation is the process of organising data to fulfil the requirements and interests of a given group or organisation. Here, the data is transformed into value. The diagram below shows all of the different data engineering tasks that happen in the direction shown.
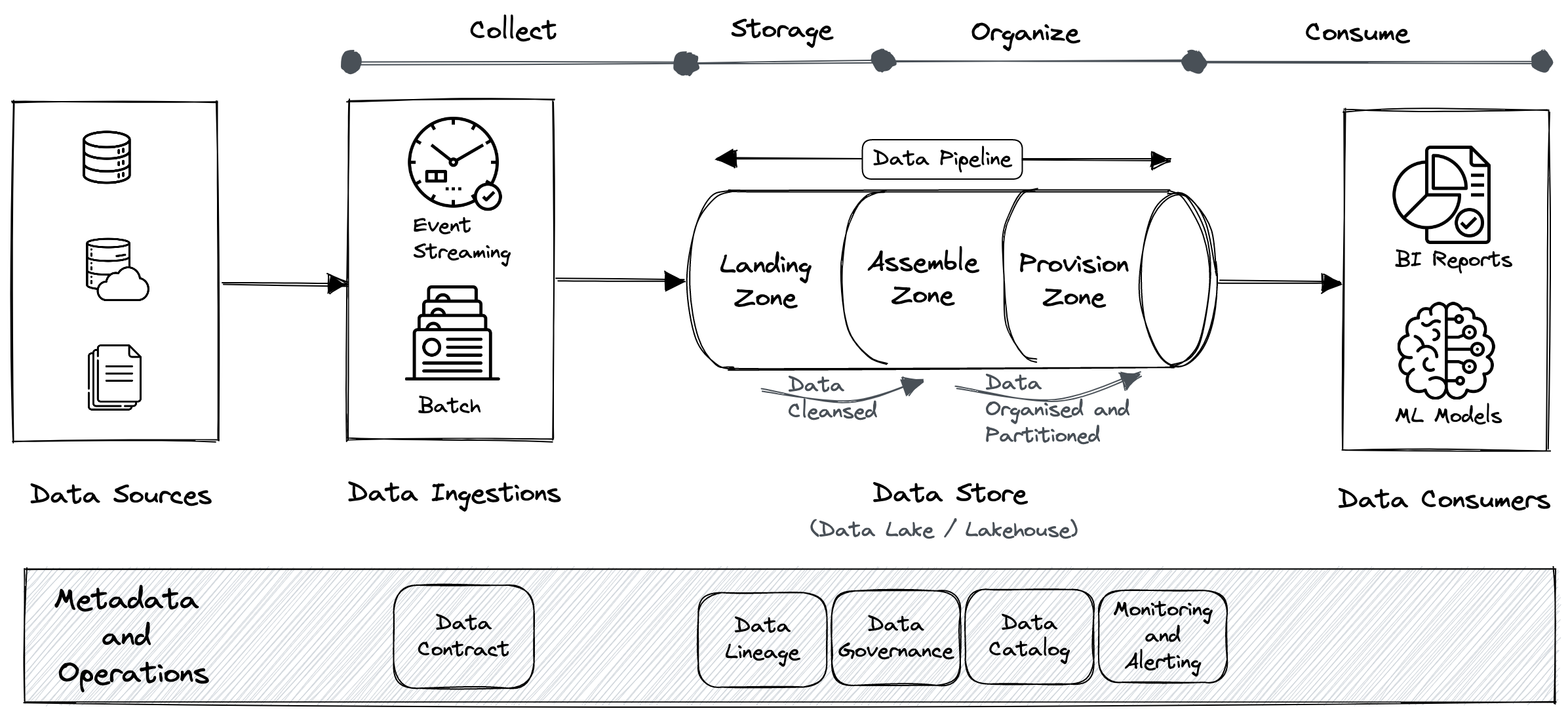 |
|
|---|---|
| Data engineering activities at a high level - By Author. |
Let’s explore each data engineering activity individually.
What is a data pipeline?
 |
|---|
| Designed by Freepik. |
A data pipeline is commonly constructed as part of data engineering to transfer data from a source to a destination. Data is transformed and optimised along the pipeline’s journey, eventually reaching a state where it can be analysed and used to generate business insights. Many of the manual processes required in processing and optimising continuous data loads are now automated by modern data pipelines.
Having stated that, data engineering’s primary task is the creation of data pipelines. They provide a seamless, automatic flow of data from one stage to another and eliminate the most of manual steps from the process. To effectively meet analytics expectations, data engineers construct a series of operations into a data pipeline that consists of many phases.
Components of a data pipeline
A data pipeline consists of several components. Each component does a specific function and contributes to the overall success of the source-to-destination data journey. The different components include:
- Ingestion
- Transformation
- Presentation
Ingestion
The first step in a typical pipeline is obtaining data from various sources like databases, files, APIs, logs, and so on, and storing it in a data lake or equivalent big data platform. The landing zone, which is essentially a dumping ground, is where data from multiple sources is first stored. Depending on the data source and business needs, data engineers may need to choose between batch or streaming (real-time) ingestion, or both. The complexity of data ingestion is related to the nature of the data source, whether static or dynamic.
Static data: Static data that normally does not change over time once it has been recorded, or if it does, it changes infrequently. It is a fixed dataset, thus it does not need refreshing. A list of nations, cities, counties, etc., would be an example of static data.
Ingestion from a static data source is straightforward, and we can get it using a scheduler-driven batch-ingestion procedure.
Dynamic data: The literal meaning of the term “dynamic” is change. When used to describe data, as in “dynamic data,” the term refers to data that is subject to change as necessary. There are several reasons why data should be dynamic. Dynamic data is mostly transactional data that is often updated, meaning it changes as new information becomes available. On an e-commerce website, for instance, product information is kept in a database and updated in real-time.
The true challenge of data ingestion emerges when such dynamic data is ingested. Data engineers must use effective change data capture (CDC) approaches to incrementally ingest data.
Ingestion types
There are two types of ingestion commonly used:
- Batch ingestion
- Event streaming (real-time)
Batch ingestion
TODO
Event streaming
The event-streaming type of ingestion is occurring in real time and is gaining popularity and becoming more common. Note that there is no true real-time ingestion capability. When collecting data from several sources and delivering it to a destination system, there is a certain amount of inherent delay in every data pipeline. So a more appropriate term would be near-real-time. The pipeline processes events sequentially as they come. Event streaming ingestion is a natural fit for several modern data source types.
Transformation
Before the ingested data is put to real use, it must undergo many actions, such as cleansing, curation, standardization, and finally aggregation. This collaborative process is known as data transformation. In other words, the data transformation process prepares data to the point where it can be readily and easily consumed for analytical processes.
Depending on the business requirements, data transformation might be a fairly complicated process. The levels of difficulty depends on a variety of factors including the following:
- Volume (size), variety (types), and breadth (how many) of data sources
- Complexity of business requirements
- Frequency of data ingestion
Presentation
Presentation is the stage where transformation outcomes are stored. This stage could be one of the following:
- Intermediate - This is where the intermediate results of the transformations are kept, and it is referred to as the silver-layer in data lakes and data warehouses.
- Final - This is where the final outputs of the transformations are kept, and it is referred to as the gold-layer in data lakes and data warehouses.
The three layers of the data lake: Typically, the data lake has the following three layers: Bronze, silver and gold. Bronze represents unaltered raw data input from data sources, silver represents filtered and cleansed data, and gold represents business-level aggregates.
Comments